Summary
 Timeseries data captures a series of observations throughout some duration. Here at the Mu Lab, we conduct a variety research in the analysis and understanding of discrete timeseries data: i.e., data where each variable takes on a finite number of possible values. This page is a collection of the past, ongoing, and future research initiatives for dealing with this type of data. Please see the specific project pages for further details. (image source)
Timeseries data captures a series of observations throughout some duration. Here at the Mu Lab, we conduct a variety research in the analysis and understanding of discrete timeseries data: i.e., data where each variable takes on a finite number of possible values. This page is a collection of the past, ongoing, and future research initiatives for dealing with this type of data. Please see the specific project pages for further details. (image source)
Clustering Techniques for Discrete Timeseries
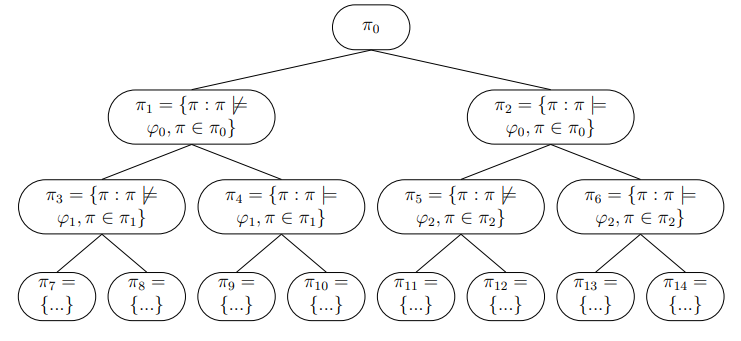 We propose a novel approach in which linear temporal logic is used to provide structure to unstructured trace data by identifying and contrastively explaining the
differences between an unspecified quantity of plan traces. By leveraging existing work focused on Bayesian inference of linear temporal logic specifications that contrast two sets of discrete timeseries trace data, we propose two novel approaches to cluster and delineate an unpartitioned set of traces.
We propose a novel approach in which linear temporal logic is used to provide structure to unstructured trace data by identifying and contrastively explaining the
differences between an unspecified quantity of plan traces. By leveraging existing work focused on Bayesian inference of linear temporal logic specifications that contrast two sets of discrete timeseries trace data, we propose two novel approaches to cluster and delineate an unpartitioned set of traces.
Planning Model Acquisition
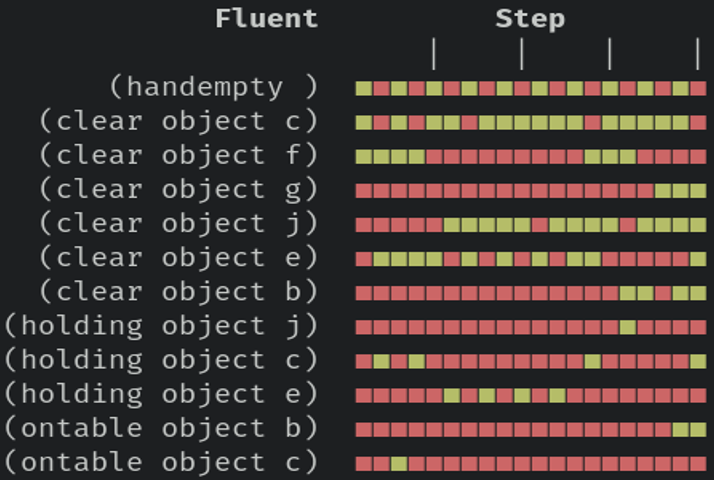 We present a holistic characterization of the action model acquisition space for automated planning, and further introduce a unifying framework for automated action model acquisition. We have re-implemented some of the landmark approaches in the area, and our characterization of all the techniques offers deep insight into the research opportunities that remain; i.e., those settings where no technique is capable of solving. Initial work on the project is wrapping up, and once released you will find the library and research [here].
We present a holistic characterization of the action model acquisition space for automated planning, and further introduce a unifying framework for automated action model acquisition. We have re-implemented some of the landmark approaches in the area, and our characterization of all the techniques offers deep insight into the research opportunities that remain; i.e., those settings where no technique is capable of solving. Initial work on the project is wrapping up, and once released you will find the library and research [here].
Discrete Latent Interpretability
 The aim is to evaluate whether representing the latent state as categorical variables encourages the “disentanglement” of concepts learned by a deep learning RL model. While full disentanglement is likely not occuring, we evaluate how different concepts are represented in the discrete latent representation to identify how the categorical variables may be benefiting the representation and obtain insight into what inductive biases may encourage better disentanglement. Read More…
The aim is to evaluate whether representing the latent state as categorical variables encourages the “disentanglement” of concepts learned by a deep learning RL model. While full disentanglement is likely not occuring, we evaluate how different concepts are represented in the discrete latent representation to identify how the categorical variables may be benefiting the representation and obtain insight into what inductive biases may encourage better disentanglement. Read More…
Office Automation

As a collaboration between the Mu Lab and the Machine Intelligence & Biocomputing (MIB) Lab, we have embarked on a research exploration to optimize several aspects of the office experience. The core motivation is to use our shared lab space as a rich source for both novel data and new research. Here, we detail both pillars of the broader initiative: data sources and ongoing research exploration.
Data Sources
Coffee machine analytics
- Description: To-the-second data from the lab’s coffee machine on the type and amount of drink requested..
- Status: Machine being secured.
- Data: Coming soon.
Tea analytics
- Description: To-the-second data on tea usage from existing supply.
- Status: Smart IoT device to monitor is being designed.
- Data: Coming soon.
Light usage
- Description: Simple measure of over-head light usage based on a sensor in the room.
- Status: Smart IoT device to monitor lighting conditions is being researched.
- Data: Coming soon.
Enivronmental sensors
- Description: Measurements of temperature, humidity, and pressure from a sensor in the room.
- Status: Smart IoT device to monitor environmental conditions is being researched.
- Data: Coming soon.
Research Questions
The following is a preliminary list of research questions / exploration that the lab members (and capstone students) will be exploring:
- Predicting coffee selection based on power usage profile.
- Predicting coffee re-supply timing so that beans neither run out or go stale.
- Optimizing tea variety preferences via evolutionary algorithms.
- Predictive analytics on the demand/usage of coffee/tea/etc in the lab.