Abstract
This project consisted of two components with the goal of automating the grading process of CISC352 assignments. The primary component focused on the grading of the PDDL assignment. This involved creating a script that merged two domain-problem pairs to check for isomorphism. The result of this process indicates whether a student’s submission aligns with the reference solution, providing a quick and efficient way to find errors within a student’s submission. The second component focused on the constraint satisfaction problem (CSP) assignment and involved KenKen boards. The automation process for this assignment involved automatically generating KenKen boards and outputting meaningful feedback for each student submission. Both the PDDL and CSP components were run on student submissions from the CISC352 course and effectively reduced marking time for the teaching team.
Introduction
Several assignments in the CISC352 Introduction to AI course are very time-consuming to mark by the teaching team, and the overall purpose of this project was to automate this process. The primary focus of the project was the automation of the PDDL Assignment grading, by devising a script using the Python tarski library
(
Citation: Francès, 2019
Francès,
G.
(2019).
Tarski Documentation.
Tarski. Retrieved from
https://tarski.readthedocs.io/en/latest/index.html
)
to identify when two problem and domain pairs are isomorphic. This enables the teaching team to automatically assess whether a student’s submission is equivalent to the correct solution template. The secondary focus of the project was to automate the grading of the Constraint Satisfaction Problem assignment, which revolves around solving KenKen boards. This problem had two aspects: automatically generating correct KenKen boards, given certain requirements as inputs, and generating meaningful feedback for common student errors.
Background
PDDL Assignment
Previously, the PDDL Assignment had been tedious to mark by the teaching team, as many valid solutions may exist when mapping a situation into the PDDL format. Previously, the PDDL Assignment had been tedious to mark by the teaching team, as many valid solutions may exist when mapping a situation into the PDDL format. The decision to automate the grading process was motivated by the idea of regular bisimulation to assess if the problems were isomorphic. Bisimiulation is the study of alignment between two dynamical systems. We considered two planning problems, one being the student’s submission and the other being the reference solution, and assessed how equivalent they were under the lens of regular bisimulation. By merging the two problems we were able to test student submissions to evaluate how correct their assignments were.
The program was written using a custom library called tarski, which enables various PDDL functionality. Among other things, it allows a user to create domains and problems using tarski objects, with all the necessary functions such as types, predicates, actions, and requirements and the ability to read and write to .pddl files. This necessitated learning the basics of tarski, which mainly meant understanding how domains and problems are stored and accessed in the API, and how pre-existing domain and problem files can be read into tarski objects, processed in specific ways into new problem and domain tarski objects, and outputted to new PDDL text files. This enabled the implementation of new domain and problem files which could be run through a planner to identify if two inputted domain-problem pairs are isomorphic. At a high level, the strategy for this was to identify if, at any point, an action in one domain would clash with the corresponding action in the other domain.
CSP Assignment
In previous years the Constraint Satisfaction Problem assignment was the n-Queens problem. The n-Queens assignment was problematic because it was very tedious to mark and solutions were too accessible online. This year the assignment was changed to the KenKen board Constraint Satisfaction Problem assignment. The main goal was to help make the marking less tedious and to automate the KenKen board construction. The first problem we solved involved implementing possible feedback for students based on common errors to reduce the time required to mark each assignment. The second problem was creating an algorithm that allowed for automating a KenKen board, this reduced the time required by eliminating the manual construction of these boards. We needed to research how to properly construct a KenKen board, we did this by manually doing KenKen boards and looking at complete solutions.
Approach
PDDL Assignment
Prior to developing a script that would determine if two problem-domain pairs are isomorphic, it was necessary to understand the fundamentals of PDDL. First, the different elements that make up the planning language were defined. These include fluents, which can be true or false, actions, which determine what the agent is allowed to do, the initial state, which fluents are initially set to true, and the goal state, the fluents the agent wants to be true. As the end goal of the project was to output a single problem-domain pair that had merged the information from the two problem-domain pairs given, it was important to understand the aspects that make the planning language.
Once this understanding of the planning language was achieved, two simple example problem-domain pairs were created. Using this state space, the first step was to create a merged problem-domain pair by hand using a PDDL editor. This provided a solution template to work off of, allowing us to compare the output from the code.
Prior to writing the script, a set of steps to create the merged problem-domain pair was created. These steps were followed in order while developing the script. It was decided that everything from the second problem-domain pair would be mapped to the first problem-domain pair. This meant that all changes and updates would be done to language one, which represented the state space of the first problem-domain pair.
First, each domain was parsed using the “parse_pddl” function from the tarski library in order to get the fluent names. Once parsed, the fluent names were stored as strings in a list. Next, new PDDL files, for both problem and domain, were created in order to update the fluent names to contain an indication of which domain the fluent originated from. For example, if there exists a fluent “on” in domain one, in the updated PDDL file it becomes “domain1_on”. This is to ensure that when the problem-domain pairs are merged, the fluents have different names. This was done using this line of code:
new_pddl_str = old_pddl_str.replace('(on', '(domain1_on')
This allows for any instance of the fluent within the file to be replaced with the updated name. The updated PDDL files were then parsed again using the tarski library.
The next step was to create failed versions of each action in the domains. It was assumed that the number, the name, and the parameters of each action were the same in both domains. However, the preconditions and the effects of the actions could be different. Two versions of the failed actions needed to be created: one where the preconditions for the action in domain one are negated and combined with the preconditions from the same action in domain two, and one where the preconditions for the action in domain two are negated and combined with the preconditions from that same action in domain one. The effect of the action was set to a newly created “failed” fluent. The failed actions were then added to the updated domain one PDDL file.
The existing actions in domain one then needed to be updated to incorporate the preconditions and effects of those same actions from domain two. A similar approach to creating the failed actions was used to merge the existing actions. The name and parameters of the actions stayed the same, while the preconditions and effects were changed. To update the preconditions, the preconditions from domain two were added to the pre-existing action preconditions in domain one. To update the effect, the effect from the action in domain two was combined with the existing effect for the action in domain one.
The final update to make was to merge the initial state and the goal state. The initial state from the second problem-domain pair was parsed and added to the first problem-domain pair. The updated goal was set to the “failed” fluent. As the last step, language one, now completely merged with the elements from the second problem-domain pair, was written to the new problem and domain PDDL files. These files are the output.
CSP Assignment
KenKen Board Generation
The first requirement for the automation of the CSP assignment was to auto-generate valid KenKen boards given the input constraints of board size, type of operands to use, and minimum and maximum cage sizes. Previously boards had been hardcoded by hand for testing purposes, so automating this process was anticipated to save the teaching team substantial amounts of time.
The first step in this process is to pick an initial number of cages based on the size n of the board, as boards are n x n. A random number of cages num_cages is selected in the range of ([size^2 / min],[size^2 / max]), for min equal to the minimum cage size requirement, and max equal to the maximum cage size requirement. The next step is to assign an initial position for each of the num_cages cages. An observation was made that by not initially considering the corners of the board as options for initial cage spots, the generator algorithm performed better, so the original positions for cages are never chosen to be corner positions.
After initial spots are assigned for each cage, each cage has adjacent cells added to it until all cages are at least size min by searching randomly around each element in the cage for unassigned cells. This was achieved by randomly shuffling the arrays holding the current cage elements, and shuffling the possible search directions, and then iterating over these two arrays in a nested for loop, thus guaranteeing that every option is searched but in random order. The next step in the algorithm is to attempt to add all the remaining unassigned cells on the board to existing cages, by popping cells from the list of remaining board cells and attempting to assign them to an adjacent cage.
At this point, it is possible that some cages have grown to exceed the max cage size. The original approach for solving this issue was to go through the cages and attempt to split overly large cages into smaller cages, and join overly small cages with adjacent cages if some cages are still less than min size. This approach was challenging to implement, so instead, a simple validation test was created to test generated cages for correctness. This test simply checks that all cage lengths are in the range [min, max]. Instead of being guaranteed to create a valid layout in a single attempt, the generator function repeatedly generates boards until a valid board is created. Next, it was determined how many iterations of this generator were required until the random nature of the algorithm would produce a correct result, and these results were used for performance measurements. It was found that the performance was overall fairly good, and so this final slicing and merging step was never implemented.
After achieving valid cages, the final step of the generator algorithm is to produce achievable operands and target numbers for each cage according to the operand restrictions from the initial input. A cage of size 1 is always given the operand ?; size 2 has a random operand from the inputted operands, stored in op; for anything larger than 2, division and multiplication are not chosen. Next, reasonable values are inputted into the cage depending on the type of operand. Specifically for multiplication, it is ensured that the goal value of the cage can be obtained by multiplying the number of integers contained in the cage.
Finally, the generated board is returned using a specific format. It is stored as a tuple, where the first element is the board size n, and the second element is a list of cages. In the list, cages are stored as tuples of: the goal cage value, a list of board tuple coordinates, and the required operand. An example of the format is as follows:
(3, [(3600, [(2, 3), (1, 3), (1, 2), (3, 3)], '*'), (13, [(2, 1), (1, 1), (3, 1), (3, 2), (2, 2)], '?')])
Automated Feedback
This section of the project required implementing an automated feedback process to an existing course assignment. Access to all files associated with the assignment was given to us to edit, allowing for the creation of this automatic feedback component. The first requirement was to get the autograder.py file within the solution folder to run for the CSP assignment, as this is where it was decided to make edits to the code. When initially running this file, there were errors in the import statements. The files that were trying to be imported from within the folder were named differently from the import statements in autograder.py which was causing the errors. A similar issue was also found to be occurring with the function names. This was fixed by ensuring the proper file and function names were being called in the correct locations. Once this was done, the autograder.py file was able to run without error.
The autograder.py file contains multiple classes and functions that have different test cases that the student’s submitted code must pass in order to achieve a perfect score on the assignment. The next step was to understand these different test cases, mainly which situations would cause the code to fail. The test cases are designed to check multiple aspects of a student’s code, however, they are set to stop at the first error encountered and register this as a failure for that test case. For example, a test case checking a student’s implementation of a forward checking constraint propagator will consist of two parts: one that checks that the board is valid, meaning it has all different constraints, and check that the valuations for the cages are correct. If a student has incorrectly implemented a forward checking constraint propagator then this test case will fail. Some examples of improper implementation could include pruning a variable that has already been pruned or not handling deadends properly. The information from these test cases was then used to generate a list of common errors that students may have encountered when writing their assignment solutions that could have caused these tests to fail. Having this list in place would allow the teaching team to provide students with more meaningful feedback without adding additional time to the marking process.
The next step was to create a dictionary that stored the feedback and scores for each student. The dictionary created is called FeedbackDict and it has key/value pairs for each test case. This dictionary would flag which test cases failed by checking if a student passed the test cases with a perfect score. If a student’s code failed a test case, then the key corresponding to that case would be given the value “Expected output from student code did not match the expected output of test cases.”, indicating that this is where there was an issue in the submitted code. For example, if a student’s code fails on the fc_score tests then the key for this function is “fc” and it will be given the error message as it’s associated value, letting the teaching team know that this question is flagged for that student.
The next action was to create another dictionary to store the list of common errors that had been previously created. This second dictionary is called CommonErr and uses the same keys as the FeedbackDict to represent the test cases. For each test case key, the corresponding value takes on a list of common errors that could cause those tests to fail. For instance, if the FeedbackDic flagged the fc_score, the CommonErr dictionary will have the same key “fc”, with the value “pruned a variable that’s already been pruned, had the wrong variable assignment for the input, didn’t handle deadends properly.” The value message lets the marking team know the possible reasons why a student’s code could fail on the fc_score functions tests.
The final step was to write the two dictionary results and the student’s code grade based on their passed/failed tests to a json file. The approach involved creating a json file for each student’s solution that outputted another dictionary called stfeedback. This dictionary combines the FeedbackDic dictionary, commonErr dictionary, and the results, which are stored in a text file and contain which tests the student passed or failed, to the json file. Below is an example output of the feedback within the json file.
Evaluation
PDDL Assignment
According to the theory of regular bisimulation, the PDDL script is capable of identifying if a student submission is equivalent to a reference solution in a one-to-one relationship. In addition, the planner outputs a plan showing the sequence of actions that caused the failed fluent to be reached, thus making it much easier to determine the cause of the error.
The PDDL script was evaluated on student submissions from the Winter 2022 CISC 352 course. The assignment required students to write a domain to model a situation, as well as three instances of problems, with increasing levels of complexity. The student submissions were checked for correctness in two ways. First, they were run through a PDDL planner unchanged to determine if it could successfully solve the domain-problem instance. Second, they were run through the PDDL script to output a merged domain-problem pair, which was then run through a PDDL planner to determine if the failed fluent could be reached. If a failed fluent was reached, this meant that the two files did not align since reaching a failed fluent entailed that one model could perform an action while the other could not.
This process highlighted the robustness of the PDDL script. In many cases, the student submission could successfully run through a planner without errors, indicating that the solution was correct. However, by testing it through the PDDL script, the planner found issues that would have otherwise gone undetected. The process of testing through bisimulation even found an issue with the original reference solution, namely that the hero was allowed to return to the start position when this should not be allowed, proving that it is superior to simple human evaluation. This same error was found in approximately 60% of student submissions, reinforcing the usefulness of this testing process as it was able to identify common errors across student submissions. Below is a sample output from an excel spreadsheet that was used to keep track of student’s grades and errors. The align column records the alignment of a student’s model against the reference solution, this was where the concept of bisimulation played a role.

Below is an example output of running a student submission through this evaluation process. The column labeled Solve shows the success of a student’s submission against certain problem instances, with the checkmarks indicating that the student’s code successfully solved the problem. The Aligns (Incorrect) column shows the result of checking for isomorphism with the original incorrect reference solution. This column is all X due to the error in the original solution, not the student submission. The Aligns (Fixed) column shows the results of checking for isomorphism with the new, correct reference solution. As can be seen, the student’s model correctly solved p01 and p02, but for p03 the script found a misalignment that was not identified by running the submission through a planner, thus demonstrating the efficacy of the script.
| Problem | Solve | St-Validates | Ref-Validates | Aligns (Fixed) | Aligns (Incorrect) |
|---|---|---|---|---|---|
| p01 | ✔ | ✔ | ✔ | ✔ | ❌ |
| p02 | ✔ | ✔ | ✔ | ✔ | ❌ |
| p03 | ✔ | ✔ | ✔ | ❌ | ❌ |
| p04 | ✔ | 23 | - | - | - |
For the p03 entries in columns Aligns (Fixed) and Aligns (Incorrect), the dashes represent that the script took too long to finish and was terminated prematurely. This was a limitation that was encountered with the script where the merged domain-problem pair would require too much time and resources to find a failed outcome when run through a planner. For example, for the third problem of the assignment, which is the most complex, the script sometimes took over 5 minutes to run through a planner and therefore was not feasible to run to completion for all students in the class.
CSP Assignment
The primary metric for evaluating the performance of the KenKen board generation algorithm is time complexity. While the generator only needs to be run several times to create example boards for assignment testing, and so time is not a significant issue, it was nonetheless desirable that the algorithm would produce results for standard requirements in a reasonable amount of time.
To this end, the generator was written in such a way as to track performance for testing purposes. Global variables are stored, where total_iterations stores the total number of iterations the generator requires to generate a given board. Variables min_failures and max_failures are used to determine if the algorithm was failing because of a cage being smaller than min or a cage was larger than max, respectively. At the bottom of the file, in the if __name__ == "__main__":, testing is performed to determine how the algorithm performs for varying input specifications.
The first testing scenario involves holding min and max constant at 2 and 6 respectively and varying the board size n, from 3 to 14. Note that min_failures + max_failures + 1 = total_iterations, as the generator can fail due to one of the two constraints not being met, and then requires one additional correct iteration to output a valid board.
| Board size | Average number of iterations | Min_failures | Max_failures | Average time (secs) |
|---|---|---|---|---|
| 3 | 1.05 | 0.01 | 0.04 | 0.0001 |
| 4 | 1.82 | 0.44 | 0.38 | 0.0002 |
| 5 | 2.99 | 1.28 | 0.71 | 0.0005 |
| 6 | 5.67 | 2.58 | 2.09 | 0.0015 |
| 7 | 9.52 | 4.32 | 4.2 | 0.0037 |
| 8 | 21.71 | 10.86 | 9.85 | 0.0122 |
| 9 | 35.03 | 16.67 | 17.36 | 0.0271 |
| 10 | 87.1 | 41.62 | 44.48 | 0.098 |
| 11 | 199.65 | 95.5 | 103.15 | 0.3481 |
| 12 | 572.2 | 268.2 | 303.0 | 1.2189 |
| 13 | 1429.8 | 661.1 | 767.7 | 4.3749 |
| 14 | 3177.1 | 1453.9 | 1722.2 | 11.8408 |
As is shown in the table, the performance drops off sharply for incremental increases in n, appearing to be increasing exponentially. This can be seen more clearly in the graph below. This is due in part to the time complexity of the generator_helper itself, as well as to the fact that the number of calls to this helper function increases sharply, as can be seen in the column for Average number of iterations.
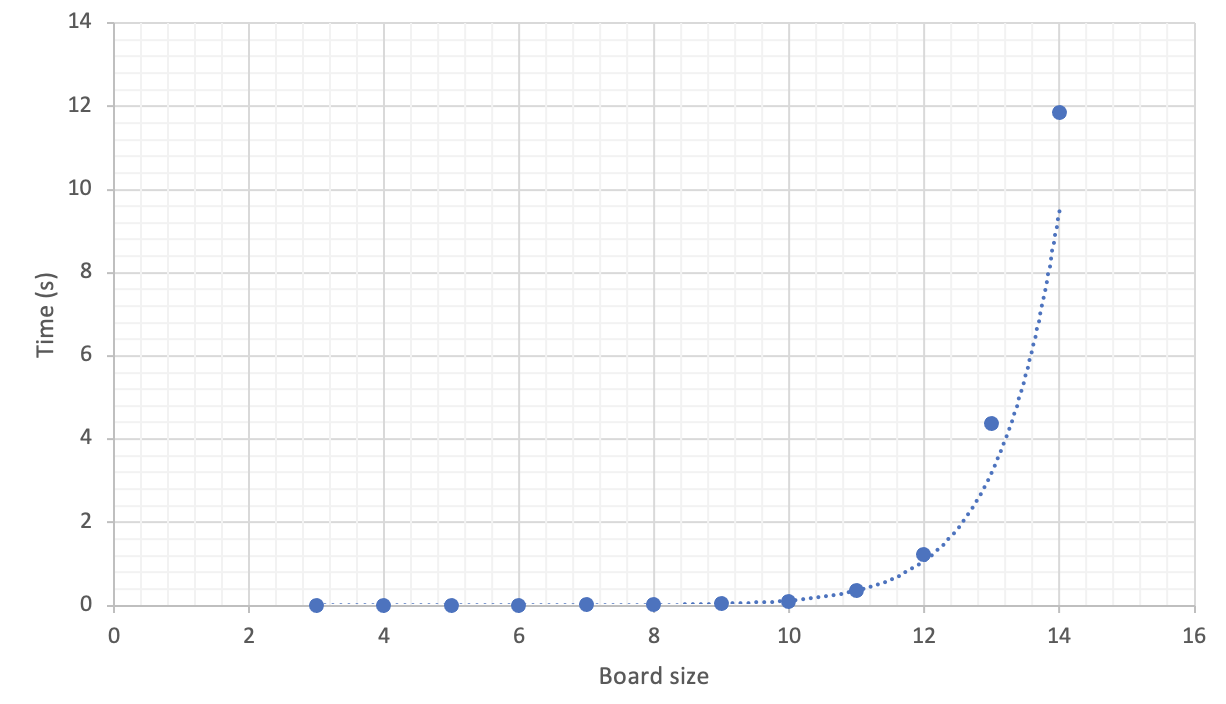
Below is a table gauging performance for varying values of min and max. As can be seen, the performance is quite similar for variations on these, and the performance only drops when min is close in value to max, which makes sense as this limits the number of possible board formats.
| Min | Max | Average iterations | Min_failures | Max_failures | Average time (secs) |
|---|---|---|---|---|---|
| 1 | 4 | 1.32 | 0.0 | 0.32 | 0.0002 |
| 1 | 5 | 1.14 | 0.0 | 0.14 | 0.0001 |
| 1 | 6 | 1.2 | 0.0 | 0.2 | 0.0001 |
| 1 | 7 | 1.08 | 0.0 | 0.08 | 0.0001 |
| 2 | 4 | 3.36 | 0.86 | 1.5 | 0.0003 |
| 2 | 5 | 2.03 | 0.63 | 0.4 | 0.0002 |
| 2 | 6 | 1.85 | 0.46 | 0.39 | 0.0002 |
| 2 | 7 | 1.82 | 0.64 | 0.18 | 0.0002 |
| 3 | 4 | 6.62 | 1.28 | 4.34 | 0.0007 |
| 3 | 5 | 2.94 | 1.05 | 0.89 | 0.0003 |
| 3 | 6 | 2.73 | 0.89 | 0.84 | 0.0003 |
| 3 | 7 | 1.95 | 0.61 | 0.34 | 0.0002 |
For the meaningful feedback component, a json file is created for each individual student after running that student’s submision against the test cases. Below is a sample of the json file output. Each key within the score dictionary is associated with a function that contains specific tests to evaluate the correctness of the students code. The value associated with each key represents the score that the student achieves for each individual test. This is displayed in the “scores” section of the json file. The “commonErr” section of the json file shows the possible errors a student could have made that resulted in a failed test. The final “output” section of the json file represents the contents that are saved in the results.txt file. The results.txt file indicates whether or not a student passed or failed the test cases. The json file merges the rsults.txt so that all the output is in one single file, to consolidate the feedback information for an individual student submmision. Overall, the automation of feedback for the CSP assignment allowed for this single json file to be used by the marking team to see possible reasons as to why a student didn’t get a perfect score.
{
"summary": {
"Student": "base_solution",
"scores": {
"FC": 2.0,
"GAC": 3.0,
"MRV": 1.0,
"DH": 1.0,
"BINARY": 1.0,
"NARY": 1.0,
"CAGE": 2.0,
"TOTAL": 11.0
},
"FC": 2.0
},
"commonErr": {
"fc": "pruned a variable that's already been pruned, had the wrong variable assignment for the input, didn't handle deadends properly",
"gac": "incorrect removal of variable when making arc consistency",
"mrv": "didn't assign most constrained value first",
"dh": "incorrectly assigned values to variables based on degree of constraints",
"binary": "...",
"nary": "...",
"cage": "..."
},
"output": "test_bne_grid_1 (__main__.TestBinaryGrid) ... ok\ntest_bne_grid_2 (__main__.TestBinaryGrid) ... ok\ntest_bne_grid_3 (__main__.TestBinaryGrid) ... ok\ntest_bne_grid_4 (__main__.TestBinaryGrid) ... ok\ntest_bne_grid_5 (__main__.TestBinaryGrid) ... ok\ntest_cages_1 (__main__.TestCageConstraints) ... ok\ntest_cages_2 (__main__.TestCageConstraints) ... ok\ntest_cages_3 (__main__.TestCageConstraints) ... ok\ntest_cages_4 (__main__.TestCageConstraints) ... ok\ntest_cages_5 (__main__.TestCageConstraints) ... ok\ntest_cages_6 (__main__.TestCageConstraints) ... ok\ntest_dh_1 (__main__.TestDH) ... ok\ntest_dh_2 (__main__.TestDH) ... ok\ntest_dh_3 (__main__.TestDH) ... ok\ntest_dh_4 (__main__.TestDH) ... ok\ntest_mrv_1 (__main__.TestMRV) ... ok\ntest_mrv_2 (__main__.TestMRV) ... ok\ntest_mrv_3 (__main__.TestMRV) ... ok\ntest_mrv_4 (__main__.TestMRV) ... ok\ntest_nary_grid_1 (__main__.TestNaryGrid) ... ok\ntest_nary_grid_2 (__main__.TestNaryGrid) ... ok\ntest_nary_grid_3 (__main__.TestNaryGrid) ... ok\ntest_nary_grid_4 (__main__.TestNaryGrid) ... ok\ntest_prop_fc_0 (__main__.TestPropFC) ... ok\ntest_prop_fc_1 (__main__.TestPropFC) ... ok\ntest_prop_fc_2 (__main__.TestPropFC) ... ok\ntest_prop_fc_3 (__main__.TestPropFC) ... ok\ntest_prop_fc_4 (__main__.TestPropFC) ... ok\ntest_prop_GAC_0 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_1 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_2 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_3 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_4 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_5 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_6 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_7 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_8 (__main__.TestPropGAC) ... ok\ntest_prop_GAC_9 (__main__.TestPropGAC) ... ok\n\n----------------------------------------------------------------------\nRan 38 tests in 2.336s\n\nOK\n"
}
Summary
The assessment grading process for the CISC 352 course was greatly improved overall through automation. In the case of the PDDL assignment, both the quality of the grading was improved, as our script highlighted errors in student submissions that may have otherwise gone unchecked, as well as greatly reduced the time required to mark a submission. Previously, a TA would have to search through an entire submission to find errors, whereas, with the implementation of our PDDL script, the error would be immediately apparent.
In the case of the CSP assignment, the time required to test student submissions on KenKen boards was greatly reduced. Instead of manually inputting valid boards, which can be very time-consuming for larger boards, the teaching team can now easily generate boards automatically with specific requirements. Furthermore, the implementation of automatic feedback generation provided a way for TAs to give higher quality feedback in less time, as well as flagging the exact location of a student’s error. Similar to the PDDL script, this enabled TAs to better utilize their time by only checking that specific region of the submission, as opposed to its entirety.
In addition to improving the quality and time efficiency of grading for CISC 352, the work involving the PDDL script is a meaningful contribution to the domain of planning. The script for merging planning problems, according to the theory of bisimulation, proved a better understanding of the alignment between two planning problems.
Further work for this project can focus on continuing to automate the remaining assignments in CISC 352. Furthermore, for future offerings of the course, assignments can be weighted less compared to tests, and be used to improve student learning. The PDDL script can be stored in a cloud service along with a reference solution, allowing students to test their assignment solutions against the reference solution, and correct their errors prior to submitting, leading to a more active learning approach in the course. For the CSP automation, further work on this project can involve using the KenKen generation script to automatically generate board instances of varying degrees of difficulty. This could be useful both for this assignment and others to generate problems for assignments of ranging difficulties.
References
- Francès (2019)
- Francès, G. (2019). Tarski Documentation. Tarski. Retrieved from https://tarski.readthedocs.io/en/latest/index.html